Why We Should Think About a Domain Specific Computer Language (DSL) for Scholarship
Introduction
This is the text of a paper I presented during the conference “Digital Hermeneutics in History: Theory and Practice”, organized by the C2DH of Luxembourg University on 25 and 26 October 2018. I have been toying with the idea for a Domain Specific Language for textual scholarship for over a decade. Manfred Thaller—not aware as far as I know of my idea—has propelled it out of its dull momentum again for me by a wonderful blogpost that he published in April (Thaller 2018). Manfred’s propositions seem to converge to a great extent with mine, and this text is greatly indebted to his blogpost. I intend to develop my preliminary argument here into an article describing a more concrete proposal for a DSL. This post is therefore a heartfelt Request For Comments (RFC) in the hope that interested people from all sides of the involved spectrum—computer scientists, software engineers, textual scholars and Science & Technology Studies researchers—will want to enter a into a dialogue on the subject
1. The Watershed Anecdote
I have been pitching the idea of a humanities specific computer language for years now. The pitch has become an almost perfect tool to separate scholars in the humanities on the one hand from software engineers and digital humanists on the other hand.
Scholars immediately love the idea of a computer language that is modelled after their knowledge domain and uses verbs and lexical items they can actually understand and apply. But engineers and digital humanists at best will roll their eyes when I mention the idea, and in some worse cases they indeed got very annoyed at the suggestion.
I think this watershed points us to a problem that we need to address: scholars feel out of their depths with current main stream general purpose computer languages. It seems however that the persons that could address it (software engineers, computer scientists, and digital humanists) are not too interested in pursuing a solution.
This problem has many roots in the history of philosophy and science, but here I want to cast it specifically as a problem of digital hermeneutics.
2. Two Main Problems
2.1. Problem One: Most Scholars are Computationally Illiterate and Digital Hermeneutics Requires Code Literacy
Hermeneutics is the theory and the methodology of interpretation. For more than two millennia it has been the main critical tool of humanists to examine texts and other sources of information. Its importance for a large part stems from the pivotal task of interpreting the Holy Scriptures during medieval and early modern times. An interesting aspect of hermeneutics is that method and object mostly coincide: in the far majority of cases text is interpreted and criticized by creating more text. In a culture where text is the main medium of knowledge creation and exchange this makes sense.
It is doubtful however if text is indeed still the linchpin medium of current human culture. Arguably it is more precise to say that nowadays digital information is the main medium of knowledge creation and exchange. Therefore scholarship should in part mean being able to interpret digital information. As pointed out however, virtually no scholar has the skills to do so.
The arguments against my proposals for a DSL for scholarship usually run largely along the line that one does not need to understand how a printing press works to read print, or that one does not need to build a printing press, or even operate it, to do so. Similarly therefore—goes the reasoning—one does not need to understand software code to appreciate the message it conveys in the form of text and images in a Graphical User Interface (GUI). Besides, the opponents reason, scholars are interested in the underlying processes and the methods and not in a particular piece of code which is just a particular expression of those analytic processes.
Such reasoning is dangerously flawed and creates a very real problem of digital hermeneutics, because it denies a primary site of interpretation: the software code that underpins all digital information.
Let me explain this further by first explaining what happens when we interpret.
2.1.1. What is Interpretation?
It is a little ridicule to suggest that yards of shelf space including that for Gadamer’s tome “Wahrheit und Methode” can be summarized in one short and neatly universal fitting definition of ‘interpretation’. However, for the argument here it is sufficient to use a slightly circular working definition of “interpretation” as the applied or practical form of hermeneutics. Umberto Eco in The Theory of the Sign and the Role of the Reader (1981) describes text essentially as a stream of reading instructions. Interpretation, or meaning creation, is then the iterative and reflexive process based on these reading instructions. Eco opposes this process of meaning creation to the idea of meaning as a linguistic identity. What he mean—or at least how I take it—is that there is no identity between sign and meaning. A sign ‘a’ is not locked to meaning ‘b’ (a ≡ b), rather a sign is ‘adorned’ with meaning during the reflexive process of interpretation which is influenced by both the linguistic context in the text and the semantic context in the mind. This process and reflexivity create what Charles Sanders Peirce called ‘infinite semiosis’, which in effect is the ability of signs to infinitely evoke new meaning.
From this fast paced comprehensive stride through theory we derive the useful observations that interpretation is the attribution of a particular meaning to information and that meaning is an emergent property of processing information. The salient point being that interpretation—or meaning attribution—is a by all means a process.
2.1.2. Why the Usual Metaphors are Flawed
My argument is that because information processing is essential for interpretation the metaphors usually set in opposition to a Domain Specific Language for the humanities are flawed: they create a false image of processing information without interpretation—as if code solely results in neutral transformations of information. The metaphors pitched against a DSL for scholarship (or against coding by humanists in general) picture code as a thing instead as a process. The two most used are ‘car’ and ‘microscope’.
The car metaphors comes in variants, but usually the engine is compared to the computer, the gasoline to the software, and the driver obviously to the user. The metaphor of the car suggests that a computer is mechanical immutable and that software is a homogeneous neutral force. It also suggest the user is unproblematic in control of both. The microscope metaphor has probably been popularized through Ian Hacking’s widespread philosophy of science piece “Do We See Through a Microscope?” (1981), although he did not use it as a metaphor for computer or software. The metaphor of the computer or software as a microscope suggests again that code is neutral by comparing it how a microscope is physically and materially neutral to the passing of light which is governed by a mathematically neutral theory of optics and tested with known visual materials.
Of course these metaphors by themselves are already completely flawed. Software is everything but a homogeneous substance as any software engineer will tell you. Software is understood mostly as a technical and impartial tool, but it is also or even primarily a culturally situated human made artefact.
But the usual metaphors are especially pernicious in what they want to suggest: that one does not need to know how these machines work to operate them and interpret their results. Of course you need to know something about the working of a microscope, even if it is just the rudimentary knowledge that it “magnifies”. If you would not have that knowledge you would take a (to you) completely harmless animal the size of a speck of dust as a three foot tall terrifying creature. Especially if we look at the concrete effect of a microscope we realize that what it does is very much a strong interpretative move. It turns a harmless speck of dust into a scary threat. It most literally changes one’s perspective.
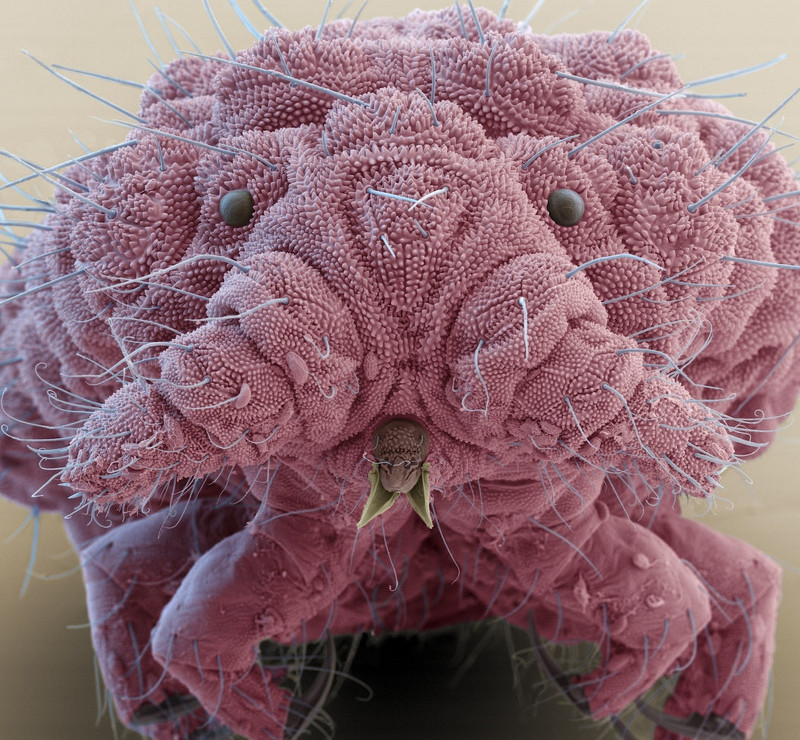
Fig. 1: Springtail, pretty harmless in real life at 6mm, kind of scary at the right magnification. (Image reproduced and cropped from https://cosmosmagazine.com/biology/micro-monsters-up-close-and-personal, credit: Eye Of Science / Science Photo Library / Getty Images.)
2.1.3. When is Hermeneutics Digital Hermeneutics
Is there anything inherent methodologically digital in analyzing a number of historic paintings from super high resolution digital images projected on a screen? If the hermeneutics applied are identical to the hermeneutic method applied in conventional art history, I would argue that this hermeneutics is indeed not in any way inherently methodological digital.
The processual dimension of hermeneutics requires that we take the full process of interpretation into account if we are to speak of true hermeneutics—i.e. meticulous methodic interpretation. The digital dimension of digital hermeneutics requires us to take into account the specifically digital aspects of that process.
Digital hermeneutics without taking into account the digital processual dimension compares to wanting to interpret a football match by the resulting score of 3 to nil alone. Methodic hermeneutics is interpreting the football match by actual watching it in process. Interpreting a football match by the final score alone can be a valid form of interpretation when it fits the purpose, e.g. to gather score statistics over a multitude of matches. But reading the match in a hermeneutic way requires a different approach, that of watching and experiencing it. Similarly digital hermeneutics requires an equally intimate experience of code that is involved in the process of interpretation.
Thus a truly digital hermeneutics involves a hermeneutics of the specifically digital parts of the interpretation process. But this is not to say that all digital parts of such a process require close reading.
Hinsen (2017) makes a useful distinction that divides scientific software code into four layers. A first layer of general infrastructural software (operating systems, compilers, generic tools like text processors). A second layer comprises scientific software of specifically science aimed applications and libraries (SPSS, Stata, Gnuplot). A third layer comprises disciplinary software and libraries (Stylo, NLTK). Finally there is bespoke code: specific one off tailored software, used mostly transiently in a single project.
A ‘black boxing’ hermeneutics that is primarily interested in interpreting the results of a tool chain that is largely made up of thoroughly evaluated and and continuously tested generic applications and libraries may well forego on including that digital code as part of the hermeneutic process, but taking for granted the interpretational dimension of bespoke code would be methodological hazardous.
Especially bespoke code is a mechanism of interpretation that a user needs to closely read and understand if it is part of digital hermeneutic interpretation or evaluation.
Mutatis mutandis what goes for data—namely that the more heterogeneous and situated one’s data is the more hermeneutic interrogation it requires—goes for code as well: the more situational the code used the more critically a hermeneutic process needs to examine it and take it into account for any interpretation.
2.1.4. How Code Contributes to Interpretation
Code can be both transformative and generative. In its transformative guise code shifts the shape of data or information. In its generative mode it adds to information to create new or augmented information. Especially of code in its transformative guise many people hold that it is neutral, that it does not affect the essential meaning of the information it is processing. But in fact it is of course exactly doing that in veritably all cases. Take as an example a simple mapping transform where a multiplier is applied to a sinus.
o = (0.0..10.0).step(0.1).map{ |x| Math.sin(x) }
m = (0.0..10.0).step(0.1).map{ |x| 20 * Math.sin(x) }
 Fig. 2.: Depiction of how ‘o’ and ‘m’ look when plotted.[/caption]
Fig. 2.: Depiction of how ‘o’ and ‘m’ look when plotted.[/caption]
Just like the microscope this chances the perspective dramatically even if the original information is the same. Such a multiplier effect is—even if it is unintentionally—also an interpretative move: it privileges certain information, subdues other signals, foregrounds a certain perspective, and primes a certain interpretation.
In its generative mode these interpretative moves become only more pronounced. When code combines or infers information it becomes almost impossible to speak of such operations as non-interpretative. If, for instance, one is aggregating frequency information of a large corpus of literary texts and adding a logistic regression revealing a shift in elite literary word use in the long 19th century, like Ted Underwood (2015) it is rather rich not to speak of an explicit interpretative move through the code. In the sense that I have written earlier of the potential ‘deferred agency’ of code, one could call this deferred analytics or indeed deferred interpretation. The human interpreter delegates the interpretative move to the code.
2.1.5. Back to Interpretation, or: The necessity of Literacy
My reasoning so far adds up to the conclusion that interpretation is spread throughout the mechanisms of code, code writing, and code application. Interpretation is fully intertwined with research method and process, and thus also with code and computation that are integral parts of that process.
Now please interpret this…

Fig. 3.: Sample of Burmese script, reproduced from Simon Ager (2018) “Omniglot - writing systems and languages of the world”, available at https://www.omniglot.com/writing/burmese.htm (accessed 30 October 2018).
Foregoing on the small chance that you actually read Burmese—and apologizing to the reader that I am assuming an audience for this article of mostly ‘cultural westerners’—this should suffice to show that there is nothing to interpret here. This is because you, reader, are illiterate in Burmese.
Now please interpret the difference between the following two simple two dimensional arrays.


Fig. 4.: Two simple comparable two dimensional matrices.
Of course we experience exactly the same thing here. Apart from maybe some ‘savants’ we are unable to see what this data might be. For interpretation we are dependent on our code microscope to augment our interpretation, which might interpret these numbers as pictures.
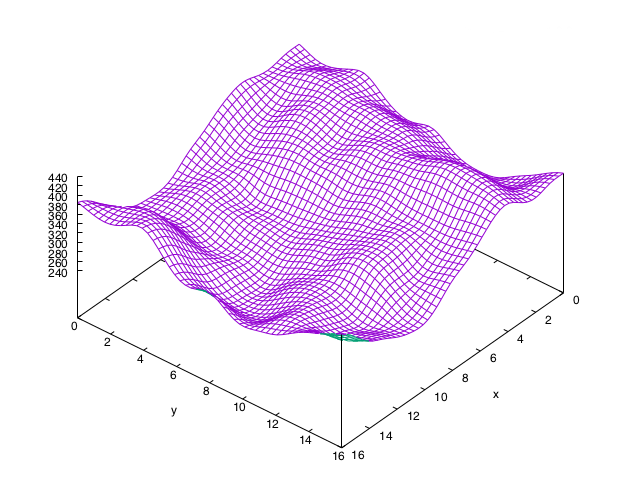
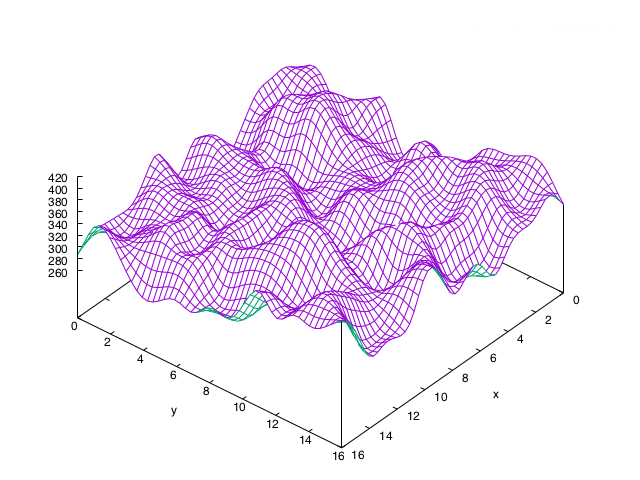
Fig. 5.: The matrices of figure 3 represented as grid surfaces.
To help us see the rather striking difference between these two sets of numbers we use code that adorns the sets with a first interpretation. Indeed like a microscope the code functions as an extension of our eyes turning these numbers more interpretable.
In the cases above we are almost fully illiterate: we cannot read or interpret either the data, the code, nor the interpretation the code creates.
Many before me have argued that if it is unknown what data means or pertains to then we cannot reliably interpret the data (Borgman 2015, Gitelman 2013). Many have likewise argued that if we cannot exactly know how a method transforms the data, then at best interpreting the results of such transformations becomes cargo culture, and at worst it results in nonsense. Because code is, as argued, a process with a similar interpretational aspect, we can only ignore it at the peril of creating illusory interpretations.
This is all to say that you cannot perform valid interpretation if you lack the ability to evaluate the interpreting method. In the case of code this means that at some level code literacy is needed to evaluate the validity of any interpretation derived in a process that included the application of that specific code.
2.2 Problem Two: Current General Purpose Computer Languages Suck From the Hermeneutic Point of View
2.2.1. Coding is Hard and Engineer Oriented
Although from a digital hermeneutics perspective code should be examined as part of the interpretation process, current general purpose computer languages try to do their utmost to keep scholars out of the process.
Having programmed since the early 1980s it surprises me still that so called high level languages are still so low level in many respects. A thing as simple as reading a file is surrounded by a baffling amount of engineering clutter. The shortest one can do in Ruby is:
File.open( "my_data.txt", "r" ) { |file| file.read }
The Python is similar:
with open( 'pagehead.htm', 'r' ) as file:
output = file.read()
One wonders what is wrong with or impossible about:
Use "some_file"
The problem is that current main stream computer languages are fully enveloped in an object oriented philosophy that puts the objects, structures, and operations of file system and data sources first and centre. They operate primarily at a level just up from the operating system, but with objects and abstractions very much below the level of any content domain. Quite logically of course, as they are indeed general purpose languages geared towards software engineers. They are languages made by engineers for engineers. They offer the user a code execution environment with the technical objects familiar to the coder: input and output access to the file system, some primitives like string, integer, and array, a few flow control and boolean operators. The idea is that from these primitives coders build a conceptual object oriented perspective of the problem domain. Some libraries indeed go a long way in that direction, although most are statistics or NLP oriented (NumPy, NLTK).
The result is that a scholar who wants to manipulate domain information finds him or herself wasting most of the time in dealing with the scaffolding stuff of system calls, pipes, and data structures rather than with actual analytic interpretative code.
This problem is aggravated by a vicious circle of software development and architectural bloat that has continued for over twenty years. There is a much longer story to tell about this (Prokopov 2018), but suffice to say that once it was plenty enough to know 13 HTML tags to be a web developer, while now it takes knowledge of HTML, CSS, JavaScript, NodeJS, Angular, Grunt, etc. etc. Next to a single language, software engineers nowadays often will use development frameworks, web frameworks, testing frameworks, integration frameworks, build frameworks, virtualization frameworks, and deployment frameworks to make their work smooth sailing.
2.2.2. Information vs Data
Technologists—computer scientists, software engineers, digital humanists—generally think of computing as the modelling, transformation, and analysis of data. However, scholars with a hermeneutic propensity are most of the time not interested in computation over data but in reasoning over information. Information usually is defined as data in context: “1 degree Celsius” is data, “1 degree Celsius on 5 July 1995 in Amsterdam” is information. The current patterns of code development are primarily focused on structuring and transforming data to visualize it in ways that end users may interpret it in a graphical user interface. This approach to computing drives the computational and the hermeneutic paradigms rather apart than towards each other. (For a more in depth treatment of this aspect turn to Thaller 2018.)
2.2.3. Algorithm vs Reasoning
By virtue of serving to almost all the needs of industry veritably all general purpose computer languages are first order logic languages—also called predicate logic languages. The ramification is that general purpose computer languages are hermeneutically poor because out of the box they only support boolean reasoning. Hermeneutics is not based on boolean comparisons, but on abductive reasoning: it tries to find the most plausible argument that combines or explains sparse and heterogeneous data.
The absolutism of boolean reasoning implies that variables in general purpose computer languages can only hold one value:
a = b
Abductive reasoning however requires a lot of leeway in the value of any variable, because it allows for ambiguity, uncertainty, possibility rather than probability. Thus in abductive reasoning
a = b & a = c
is an assignment, not a comparison.
A lot of these characteristics of abductive reasoning can actually be supported through probabilistic computing. Indeed general purpose languages can come a long way in supporting probabilistic reasoning. However, this has to be done by creating several abstraction layers in such a language that together then make up a probabilistic reasoning engine. None of them is probabilistic at the ‘bare metal’. But even if they were: probabilistic reasoning is still not exactly abductive reasoning. Probabilistic reasoning considers a statement true because it is ‘probable’, and it is probable because there are enough prior examples of the statement being true (e.g. all ripe bananas are yellow). Abductive reasoning however, even allows for leaps of imagination that go beyond ‘plausible’ and have little or no support in prior examples. In abductive reasoning facts may be ‘imaginable’, for instance, rather than ‘probable’ or ‘true’.
These are probably the most fundamental differences between current general purpose computer languages and a more hermeneutically inspired computer language.
3. Problems 1 and 2 Lead to the Central Problem: the Renaissance Man Deadlock
I have demonstrated that there is a real need for scholars to engage with code and to engage with code in a hermeneutic fashion. Current general purpose computer languages however because of their low level, data oriented, first order logic nature resist such hermeneutic engagement. These languages are thus not very inviting or attractive for scholars to learn and to apply.
Most certainly general purpose computer languages can be stretched to serve as more hermeneutically inclined tools, e.g. along probabilistic approaches. The problem however, is that to do so requires a level of code literacy that is even beyond the coding fluency that is needed to just understand general purpose computer languages in their guise as first order computing languages.
Thus to have scholars work around the fact that current general purpose computer languages are pretty horrible digital hermeneutic instruments, you need to ‘upgrade’ these scholars to a level of computer language proficiency that is not even average in the software engineering domain.
But a person can be only so much expert in so many fields. You cannot turn humanities scholars into expert coders and have them being expert humanists as well. It is nigh impossible to be both an expert coder and simultaneously be an expert in a humanities topic sufficiently to be productive at an academic level. This is what I mean by the Renaissance Man Deadlock: if you try to be expert in both directions, you will suck at both. Excelling at both makes you a kind of scientific unobtainium (Unobtainium 2018).
4. Towards a Solution: If the Mountain Will Not Come to Mohammed, Mohammed Will Go to the Mountain.
Or in other words: we need better computer languages that are more geared towards hermeneutics.
4.1. What Might a DSL for Scholarship Look Like?
First of all such a language would be far more high level than anything we are used to so far. It would certainly abstract away completely from the low level file system and piping calls that are now often needed to accomplish anything useful but that require the bulk of the programming time. So it indeed would implement something like Use "my_data.json".
This suggestion itself may send IT architects screaming for all the security holes and error prone assumptions about the underlying filesystem such a language would result in. But the salient point is that computer scientists and software engineers always face in the direction of their platforms. What I invite them to do is to instead focus a while on the question “What is the most convenient way for the scholarly users to reach for their data?”
A hermeneutic computing language’s unit of processing is information not data. Before claiming impossibilities, engineers and computer scientists should note that it is actually normal for a unit of processing to be at a higher level of bits and bytes. Data is usually already a complex structured digital object, but the challenge is not to leave it at that.
Manfred Thaller (2018) in this respect suggests to implement Keith Devlin’s idea of infons “for seamless usage in main stream programming languages”. An infon could be formally represented as:
« P, a1, a2, … t, p, 0.1 »
Meaning that certain objects (a1, a2, etc.) at a certain time (t) and place (p) have a determined relationship P with a probability of 0.1.
My quibble here would be not with the infons (I think they make sense as an atomic unit of hermeneutic information) but with “seamless usage in main stream programming languages”. As stated I think main stream programming languages are not suited for scholarship because their idiom remains at too low a level of abstraction. Infons should indeed better be implemented as part of a hermeneutics geared domain specific computer language.
A hermeneutic computing language or a DSL for scholarship should be as polyglot as possible. Coding often means spending huge amounts of time and effort piping data from one language to another (e.g. feeding data into Gnuplot from Ruby), this should be far more convenient:
def plot_grid<
grid_data = @data_points
R.set style line 2 lc rgb '#5e9c36' pt 6 ps 1 lt 1 lw 2
R.set dgrid3d 50,50 gauss 4
R.splot grid_data u 1:2:3 w lines
puts "done"</code>
This DSL I would like to see supports some form of ‘beyond boolean’ logic. For instance, the statement
a = b & a = c
in such a language would be a value assignment instead of a boolean comparison (which would conventionally be denoted by using "a == b && a == c"). The assignment itself would mean that a might be b or a might be c. This implies that such a language would allow for simultaneous computation of equivalent execution paths to compare hypotheses cast by such assignments.
A language like this might be probabilistic, but must in any case be ‘fuzzy’ to support ambiguity, imprecision, and uncertainty—because in “ca. 1564” the amount that circa signifies varies by context.
Finally a hermeneutic language would implement more flow control operators than just the conditional ‘if’. It would, for instance, implement ‘therefore’ and ‘because’ like operators, which are equivalent to ‘if’ but manipulate the order and dependency structure of argument.
I will go hungry if I do not eat
I will go hungry because I do not eat
I do not eat therefore I go hungry
5. Conclusion
Main stream general purpose computer languages are seriously flawed as hermeneutic computing languages and scholars are seriously challenged in acquiring fluency in such languages because they cannot be expert in two fields simultaneously.
Truly digital hermeneutics however require a deep and intimate engagement with the interpretative aspects of code, because interpretation is a process of which code can be, and often is, an integral part.
It is therefore that we should at least think about a domain specific computing language that will allow scholars to enter the hermeneutic space that code creates. Humanities critical role could be seriously impaired if scholars were not allowed entrance to the sites of interpretation that computer languages have created.
Indicative properties and broad outlines of a domain specific language for scholarship can be given. Also prior work in computer science exists that indicates that such a language falls within the bounds of the possible.
The ultimate challenge is to build a hermeneutics oriented computer language from the ground up. However, as first practice and baby steps higher level languages like Python and Ruby should offer plenty of sandbox space for exercises towards such an eventual new language.
To prevent it becoming some idiosyncratic idiolect, designing a language like the envisioned domain specific computer language for scholarship should not be some individual endeavour. Rather it should be an interdisciplinary and community driven development, which could well be modelled after or be part of the ‘Shared Task in the Digital Humanities’ (Reiter 2016).
–JZ_20181019_1551
References
- Borgman, C. L. (2015) Big Data, Little Data, No Data: Scholarship in the Networked World. Cambridge Mass.: MIT Press.Eco, U. (1981) ‘The Theory of Signs and the Role of the Reader’, The Bulletin of the Midwest Modern Language Association, 14(1), pp. 35–45. doi: 10.2307/1314865.
- Gitelman, L. (ed.) (2013) “Raw Data” Is an Oxymoron. Cambridge (MA), USA: The MIT Press.
- Hacking, I. (1981) ‘Do We See Through a Microscope?’, Pacific Philosophical Quarterly, 62(4), pp. 305–322.
- Hinsen, K. (2017) ‘Sustainable software and reproducible research: dealing with software collapse’, Konrad Hinsen’s Blog, 13 January. Available at: http://blog.khinsen.net/posts/2017/01/13/sustainable-software-and-reproducible-research-dealing-with-software-collapse/ (Accessed: 21 April 2017).
- Prokopov, N. (2018) Software disenchantment, tonsky.me. Available at: http://tonsky.me/blog/disenchantment/ (Accessed: 25 October 2018).
- Reiter, N. (2016) An Initiative for Shared Tasks in the Digital Humanities, GitHub. Available at: https://github.com/SharedTasksInTheDH (Accessed: 13 July 2018).
- Thaller, M. (2018) ‘On Information in Historical Sources’, A Digital Ivory Tower, 24 April. Available at: https://ivorytower.hypotheses.org/56 (Accessed: 16 June 2018).
- Underwood, T. and Sellers, J. (2015) How Quickly Do Literary Standards Change?, Figshare. Available at: http://figshare.com/articles/How_Quickly_Do_Literary_Standards_Change_/1418394 (Accessed: 16 December 2015).
- Unobtainium (2018) tvtropes. Available at: https://tvtropes.org/pmwiki/pmwiki.php/Main/Unobtainium (Accessed: 25 October 2018).